

Operate phase is where system goes live and operations team fully take over the system. Operations and incident management shall be put in place to ensure that the system is operational and users are able to access the system. In DevOps approach, where it tries to ensure continuous delivery, operations team shall automate the infrastructure provisioning such as auto scaling whenever possible in order to ensure high system availability and better performance. This will reduce the mean time to resolution and impact to the users while developer and operations teams have sufficient amount of time to resolve the incident.
Operations team can leverage on tools to improve their effectiveness in managing day-to-day operations. Table below shows examples of operation tools such as Jenkins can help to automate the deployment and recovery process, OpenShift to improve application scalability by enabling auto scaling and Bugzilla to track any bugs detected.
| Tools | Descriptions |
| Jenkins | An open source automation server that helps to automate the certain part of the software development process, with continuous integration and facilitating technical aspects of continuous delivery |
| OpenShift | An open source containerization software which operates as a platform as a service. This platform allows auto scaling where it will provision additional pods when additional capacity is required |
| Bugzilla | An open source bug tracking software that helps to track and manage any bugs found by users or operations team. This provides feedbacks to developers on issue found during operation. |
Bugzilla - Bug Tracking Tool:
Figure 2-20 Bugzilla : Bug Tracking Tool
2.10.1 Performance, High Availability and Scalability
Key factors in operating systems successfully are performance, high availability and scalability. These factors shall be thoroughly thought thru as they increase the success rate of a system going live.
Performance is defined as system throughput under a given workload for a specific timeframe. Performance is validated by testing the scalability and the reliability of hardware, software and network. It is an ongoing process and not an end result. Performance requirements undergo massive changes as features and functionalities get added and eliminated to accommodate evolving business requirements.
High availability (HA) is when your applications remain available and accessible without any interruption and serve their intended function seamlessly. HA is achieved when your database cluster continues to operate, for example, even if one or more servers are blown up, shut down, or simply disengaged unexpectedly from the rest of the network. Refer to image below for a typical HA architecture.
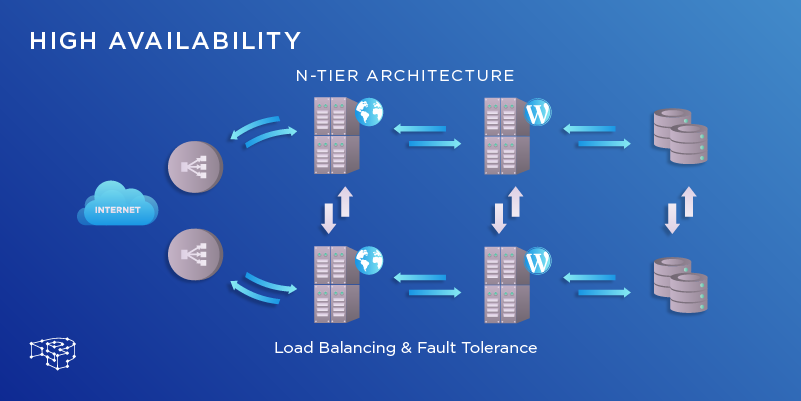
Figure 2-21 High Availability Architecture
Scalability simply refers to the ability of an application or a system to handle a huge volume of workload or expand in response to an increased demand for database access, processing, networking, or system resources. Refer to image below for an example of performance versus scalability chart while the image below it shows the difference between vertical scaling and horizontal scaling.
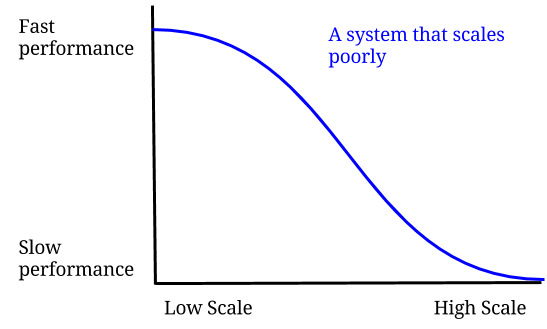
Figure 2-22 Performance vs Scalability Chart
System has high scalability when it is able to maintain fast performance on high load while system has low scalability when it has slow performance under high load.
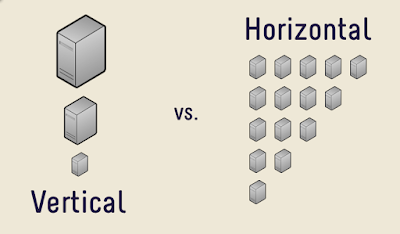
Figure 2-23 Vertical Scaling vs Horizontal Scaling
There are two common ways of scaling a system, vertical scaling and horizontal scaling. Vertical scaling is happens where the same server that is used to host the system is being added with more or powerful resources such as CPU, memory or disk. Horizontal scaling on the other hand is scaling done by adding more servers to handle the additional of load to the system. With advancement on technologies, operations team has more choices to scale the system such as utilizing virtualization, cloud or container technologies.
2.10.2 Deliverables
- Go–live or baseline report – a report to measure and indicate what is the current application and server performance and serve as a reference point for the future